By Ethan Winer <ethan@ethanwiner.com>
In Chapter 6 you learned the principles of accessing files with BASIC, and saw the advantages and disadvantages of each of the various methods. This chapter continues the coverage of file handling in BASIC by discussing the concepts of database application programming. In particular, this chapter will cover database file structures--including fixed and variable length records--as well as the difference between code- and data-driven applications.
This chapter also provides an in-depth look at the steps needed to write applications that can run on a network. This is an important topic that is fast becoming even more important, and very little information is available for programmers using BASIC. I will discuss the various file access schemes and record locking techniques, and also how to determine if a program is currently running on a network and if so which one.
This chapter examines common database file formats including the one used by dBASE III Plus, and utility programs are provided showing how to access these files. I will explain some of the fundamental issues of database design, including relationships between files. Also presented is a discussion of the common indexing techniques available, and a comparison of the relative advantages and disadvantages of each. You will also learn about the Structured Query Language (SQL) data access method, and understand the advantages it offers in an application programming context. Finally, several third-party add-on products that facilitate database application programming will be described.
Almost every application you create will require some sort of file access, if only to store configuration information. Over time, programmers have developed hundreds of methods for storing information including sequential files, random files, and so forth. However, this type of data file management must not be confused with database management in the strict sense. Database management implies repeated data structures and relationships, with less importance given to the actual data itself.
In Chapter 6 you learned two common methods for defining the structure of a random access data file. But whether you use FIELD or TYPE, those examples focused on defining a record layout that is known in advance. When the data format will not change, defining a file structure within your program as FIELD or TYPE statements makes the most sense--a single statement can directly read or write any record in the file very quickly. But this precludes writing a general purpose database program such as dBASE, DataEase, or Paradox. In programs such as these, the user must be allowed to define each field and thus the record structure.
The key to the success of these commercial programs is therefore in their flexibility. If you need to write routines for forms processing, expression evaluation, file sorting, reports, and so forth, you should strive to make them reusable. For example, if you intend to print a report from a data file whose records have 100 fields, do you really want to use 100 explicit PRINT statements? The ideal approach is to create a generic report module that uses a loop to print each selected field in each of the selected records. This is where the concept of data-driven programming comes into play.
Data-driven programming, as its name implies, involves storing your data definitions as files, rather then as explicit statements in the program's BASIC source code. The advantage to this method of database programming lies in its flexibility and reusability. By storing the data definitions on disk, you can use one block of code to perform the same operations on completely different sets of data.
There are two general methods of storing data definitions on a disk--in the same file as the actual data or in a separate file. Storing the record definition in a separate file is the simplest approach, because it allows the main data file to be comprised solely of identical-length records. Keeping both the record layout and the data itself in a single file requires more work on your part, but with the advantage of slightly less disk clutter. In either case, some format must be devised to identify the number of fields in each data record and their type.
The example below shows a typical field layout definition, along with code to determine the number of fields in each record. Please understand that the random access file considered here is a file of field definitions, and not actual record data.
TYPE FldRec FldName AS STRING * 15 FldType AS STRING * 1 FldOff AS INTEGER FldLen AS INTEGER END TYPE OPEN "CUST.FLD" FOR BINARY AS #1 TotalFields% = LOF(1) \ 20 DIM FldStruc(1 TO TotalFields%) AS FldRec RecLength% = 0 FOR X% = 1 TO TotalFields% GET #1, , FldStruc(X%) RecLength% = RecLength% + FldStruc(X%).FldLen NEXT CLOSE #1
In this program fragment, 15 characters are set aside for each field's name, a single byte is used to hold a field type code (1 = string, 2 = currency, or whatever), and integer offset and length values show how far into the record each field is located and how long it is. Once the field definitions file has been opened, the number of fields is easily determined by dividing the file size by the known 20-byte length of each entry. From the number of you fields you can then dimension an array and read in the parameters of each field as shown here.
Notice that the record length is accumulated as each field description in read from the field definition file. In a real program, two field lengths would probably be required: the length of the field as it appears on the screen and the number of bytes it will actually require in the record. For example, a single precision number is stored on disk in only four bytes, even though as many as seven digits plus a decimal point could be displayed on the data entry screen. Therefore, the method shown in this simple example to accumulate the record lengths would be slightly more involved in practice.
Once the number and size of each field is known, it is a simple matter to assign a string to the correct length to hold a single data record. Any record could then be retrieved from the file, and its contents displayed as shown following.
OPEN "CUST.DAT" FOR RANDOM AS #1 LEN = RecLength% Record$ = SPACE$(RecLength%) GET #1, 1, Record$ CLOSE #1 FOR X% = 1 TO TotalFields% FldText$ = MID$(Record$, FldStruc(X%).FldOff, FldStruc(X%).FldLen) PRINT FldStruc(X%).FldName; ": "; FldText$ NEXT
Here, the first record in the file is read, and then the function form of MID$ is used to extract each data field from that record. Assigning individual fields is just as easy, using the complementary statement form of MID$:
MID$(Record$, FldStruc(FldNum).FldOff, FldStruc(FldNum).FldLen) = NewText$
Understand that the entire point of this exercise is to show how a generic routine to access files can be written, and without having to establish the record structure when you write the program. Although you could use FIELD instead of MID$ to assign and retrieve the information from each field, that works only when the field information is kept in a separate file. If the field definitions are in the same file as the data, you will have to use purely binary file access, to account for the fixed header offset at the start of the file.
When you tell BASIC to open a file for random access, it uses the record length to determine where each record begins in the file. But if a header portion is at the beginning of the file, a fixed offset must be added to skip over the header. Since BASIC does not accommodate specifying an offset this way, it is up to you to handle that manually. However, the added complexity is not really that difficult, as you will see shortly in the routines that create and access dBASE files.
dBASE--and indeed, most commercial database products--store the field information in the same file that contains the data. This has the primary advantage of consolidating information for distribution purposes. [For example, if your company sells a database of financial information, this minimizes the number of separate files your users will have to deal with.] Modern header structures are variable length, which allows for a greater optimization of disk space. In fact, most header structures mimic the record array shown above, but also store information such as the length of the header and the number of fields. This is needed because the number of fields cannot be determined from the file size alone, when the file also holds the data.
The description of the dBASE file structure that follows serves two important purposes: First, it shows you how such a data file is constructed using a real world example. Second, this information allows you to directly access dBASE files in programs of your own. If you presently write commercial software--or if you aspire to--being compatible with the dBASE standard can give your product a definite advantage in the marketplace. Table 7-1 identifies each component of the dBASE file header.
| Offset | Contents |
|---|---|
| 1 | dBASE version (3, or &H83 if there's a memo file) |
| 2 | Year of last update |
| 3 | Month of last update |
| 4 | Day of last update |
| 5-8 | Total number of records in the file (long integer) |
| 9-10 | Number of bytes in the header (integer) |
| 11-12 | Length of records in the file (integer) |
| 13-32 | Reserved |
| 33-42 | Field name, padded with CHR$(0) null bytes |
| 43 | Always zero |
| 44 | Field type (C, D, L, M, or N) |
| 45-48 | Reserved |
| 49 | Field width |
| 50 | Number of decimal places (Numeric fields only) |
| 51-64 | Reserved |
Notes:
To obtain any item of information from the header you will use the binary form of GET #. For example, to read the number of data records in the file you would do this:
OPEN "CUST.DBF" FOR BINARY AS #1 GET #1, 5, NumRecords& CLOSE #1
And to determine the length of each data record you will instead use this:
OPEN "CUST.DBF" FOR BINARY AS #1 GET #1, 1, RecordLength% CLOSE #1 PRINT "The length of each record is "; RecordLength%
In the first example, GET # is told to seek to the fifth byte in the file and read the four-byte long integer stored there. The second example is similar, except it seeks to the 11th byte in the file and reads the integer record length field. One potential limitation you should be aware of is BASIC does not offer a byte-sized variable type. Therefore, to read a byte value such as the month you must create a one-character string, read the byte with GET #, and finally use the ASC function to obtain its value:
Month$ = " " GET #1, 3, Month$ PRINT "The month is "; ASC(Month$)
Likewise, you will use CHR$ to assign a new byte value prior to writing a one-character string:
Month$ = CHR$(NewMonth%) PUT #1, 3, Month$
With this information in hand, it is a simple matter to open a dBASE file, and by reading the header determine everything your program needs to know about the structure of the data in that file. The simplest way to do this is by defining a TYPE variable for the first portion of the header, and a TYPE array to hold the information about each field. Since both the record and field header portions are each 32 bytes in length, you can open the file for Random access. A short program that does this is shown below.
TYPE HeadInfo Version AS STRING * 1 Year AS STRING * 1 Month AS STRING * 1 Day AS STRING * 1 TRecs AS LONG HLen AS INTEGER RecLen AS INTEGER Padded AS STRING * 20 END TYPE TYPE FieldInfo FName AS STRING * 10 Junk1 AS STRING * 1 FType AS STRING * 1 Junk2 AS STRING * 4 FLen AS STRING * 1 Dec AS STRING * 1 Junk3 AS STRING * 14 END TYPE DIM Header AS HeadInfo OPEN "CUST.DBF" FOR RANDOM AS #1 LEN = 32 GET #1, 1, Header TFields% = (Header.HLen - 32) \ 32 REDIM FInfo(1 TO TFields%) AS FieldInfo FOR X% = 2 TO TFields% GET #1, X%, FInfo(X%) NEXT CLOSE #1
The programs that follow are intended as a complete set of toolbox subroutines that you can add to your own programs. The first program contains the core routines that do all of the work, and the remaining programs illustrate their use in context. Routines are provided to create, open, and close dBASE files, as well as read and write data records. Additional functions are provided to read the field information from the header, and also determine if a record has been marked as deleted.
The main file that contains the dBASE access routines is DBACCESS.BAS, and several demonstration programs are included that show the use of these routines in context. In particular, DBEDIT.BAS exercises all of the routines, and you should study that program very carefully.
There are two other example programs that illustrate the use of the dbAccess routines. DBCREATE.BAS creates an empty dBASE file containing a header with field information only, DBEDIT.BAS lets you browse, edit, and add records to a file, and DBSTRUCT.BAS displays the structure of an existing file. There is also a program to pack a database file to remove deleted records named, appropriately enough, DBPACK.BAS.
When you examine these subroutines, you will notice that all of the data--regardless of the field type--is stored as strings. As you learned in earlier chapters, storing data as strings instead of in their native format usually bloats the file size, and always slows down access to the field values. This is but one of the fundamental limitations of the dBASE file format. Note that using strings alone is not the problem; rather, it is storing the numeric values as ASCII data.
'********** DBACCESS.BAS, module for access to DBF files
'Copyright (c) 1991 Ethan Winer
DEFINT A-Z
'$INCLUDE: 'dbf.bi'
'$INCLUDE: 'dbaccess.bi'
SUB CloseDBF (FileNum, TRecs&) STATIC
Temp$ = PackDate$
PUT #FileNum, 2, Temp$
PUT #FileNum, 5, TRecs&
CLOSE #FileNum
END SUB
SUB CreateDBF (FileName$, FieldArray() AS FieldStruc) STATIC
TFields = UBOUND(FieldArray)
HLen = TFields * 32 + 33
Header$ = SPACE$(HLen + 1)
Memo = 0
FldBuf$ = STRING$(32, 0)
ZeroStuff$ = FldBuf$
FldOff = 33
RecLen = 1
FOR X = 1 TO TFields
MID$(FldBuf$, 1) = FieldArray(X).FName
MID$(FldBuf$, 12) = FieldArray(X).FType
MID$(FldBuf$, 17) = CHR$(FieldArray(X).FLen)
MID$(FldBuf$, 18) = CHR$(FieldArray(X).Dec)
MID$(Header$, FldOff) = FldBuf$
LSET FldBuf$ = ZeroStuff$
FldOff = FldOff + 32
IF FieldArray(X).FType = "M" THEN Memo = -1
RecLen = RecLen + FieldArray(X).FLen
NEXT
IF Memo THEN Version = 131 ELSE Version = 3
MID$(Header$, 1) = CHR$(Version)
Today$ = DATE$
Year = VAL(RIGHT$(Today$, 2))
Day = VAL(MID$(Today$, 4, 2))
Month = VAL(LEFT$(Today$, 2))
MID$(Header$, 2) = PackDate$
MID$(Header$, 5) = MKL$(0)
MID$(Header$, 9) = MKI$(HLen)
MID$(Header$, 11, 2) = MKI$(RecLen)
MID$(Header$, FldOff) = CHR$(13)
MID$(Header$, FldOff + 1) = CHR$(26)
OPEN FileName$ FOR BINARY AS #1
PUT #1, 1, Header$
CLOSE #1
END SUB
FUNCTION Deleted% (Record$) STATIC
Deleted% = 0
IF LEFT$(Record$, 1) = "*" THEN Deleted% = -1
END FUNCTION
FUNCTION GetField$ (Record$, FldNum, FldArray() AS FieldStruc) STATIC
GetField$ = MID$(Record$, FldArray(FldNum).FOff, FldArray(FldNum).FLen)
END FUNCTION
FUNCTION GetFldNum% (FieldName$, FldArray() AS FieldStruc) STATIC
FOR X = 1 TO UBOUND(FldArray)
IF FldArray(X).FName = FieldName$ THEN
GetFldNum% = X
EXIT FUNCTION
END IF
NEXT
END FUNCTION
SUB GetRecord (FileNum, RecNum&, Record$, Header AS DBFHeadStruc) STATIC
RecOff& = ((RecNum& - 1) * Header.RecLen) + Header.FirstRec
GET FileNum, RecOff&, Record$
END SUB
SUB OpenDBF (FileNum, FileName$, Header AS DBFHeadStruc, FldArray() AS _
FieldStruc) STATIC
OPEN FileName$ FOR BINARY AS FileNum
GET FileNum, 9, HLen
Header.FirstRec = HLen + 1
Buffer$ = SPACE$(HLen)
GET FileNum, 1, Buffer$
Header.Version = ASC(Buffer$)
IF Header.Version = 131 THEN
Header.Version = 3
Header.Memo = -1
ELSE
Header.Memo = 0
END IF
Header.Year = ASC(MID$(Buffer$, 2, 1))
Header.Month = ASC(MID$(Buffer$, 3, 1))
Header.Day = ASC(MID$(Buffer$, 4, 1))
Header.TRecs = CVL(MID$(Buffer$, 5, 4))
Header.RecLen = CVI(MID$(Buffer$, 11, 2))
Header.TFields = (HLen - 33) \ 32
REDIM FldArray(1 TO Header.TFields) AS FieldStruc
OffSet = 2
BuffOff = 33
Zero$ = CHR$(0)
FOR X = 1 TO Header.TFields
FTerm = INSTR(BuffOff, Buffer$, Zero$)
FldArray(X).FName = MID$(Buffer$, BuffOff, FTerm - BuffOff)
FldArray(X).FType = MID$(Buffer$, BuffOff + 11, 1)
FldArray(X).FOff = OffSet
FldArray(X).FLen = ASC(MID$(Buffer$, BuffOff + 16, 1))
FldArray(X).Dec = ASC(MID$(Buffer$, BuffOff + 17, 1))
OffSet = OffSet + FldArray(X).FLen
BuffOff = BuffOff + 32
NEXT
END SUB
FUNCTION PackDate$ STATIC
Today$ = DATE$
Year = VAL(RIGHT$(Today$, 2))
Day = VAL(MID$(Today$, 4, 2))
Month = VAL(LEFT$(Today$, 2))
PackDate$ = CHR$(Year) + CHR$(Month) + CHR$(Day)
END FUNCTION
FUNCTION Padded$ (Fld$, FLen) STATIC
Temp$ = SPACE$(FLen)
LSET Temp$ = Fld$
Padded$ = Temp$
END FUNCTION
SUB SetField (Record$, FText$, FldNum, FldArray() AS FieldStruc) STATIC
FText$ = Padded$(FText$, FldArray(FldNum).FLen)
MID$(Record$, FldArray(FldNum).FOff, FldArray(FldNum).FLen) = FText$
END SUB
SUB SetRecord (FileNum, RecNum&, Record$, Header AS DBFHeadStruc) STATIC
RecOff& = ((RecNum& - 1) * Header.RecLen) + Header.FirstRec
PUT FileNum, RecOff&, Record$
END SUB
Each of the routines listed above performs a different useful service to assist you in accessing dBASE files, and the following section describes the operation and use of each routine. Please understand that these routines are intended to be loaded as a module, along with your own main program. To assist you, a file named DBACCESS.BI is provided, which contains appropriate DECLARE statements for each routine. You should therefore include this file in your programs that use these routines.
A second include file named DBF.BI is also provided, and it contains TYPE definitions for the header and field information. You may notice that these definitions vary slightly from the actual format of a dBASE file. For efficiency, the OpenDBF routine calculates and saves key information about the file to use later. As an example, the offset of the first record's field information is needed by GetRecord and SetRecord. Rather than require those procedures to calculate the information repeatedly each time, OpenDBF does it once and stores the result in the Header TYPE variable.
Similarly, the field definition header used by these routines does not parallel exactly the format of the information in the file. The modified structures defined in DBF.BI are as follows:
'********** DBF.BI - Record declarations for the dbAccess routines TYPE DBFHeadStruc Version AS INTEGER Memo AS INTEGER Year AS INTEGER Month AS INTEGER Day AS INTEGER FirstRec AS INTEGER TRecs AS LONG RecLen AS INTEGER TFields AS INTEGER END TYPE TYPE FieldStruc FName AS STRING * 10 FType AS STRING * 1 FOff AS INTEGER FLen AS INTEGER Dec AS INTEGER END TYPE
CreateDBF accepts the name of the file to create and a field definition array, and then creates the header portion of a dBASE file based on the field information in the array. The file that is created has no data records in it, but all of the header information is in place. The calling program must have dimensioned the field information TYPE array, and filled it with appropriate information that describes the structure of the records in the file. The DBCREATE.BAS program shows an example of how to set up and call CreateDBF.
OpenDBF is used to open a DBF file, and to make information about its structure available to the calling program. It fills a TYPE variable with information from the data file header, and also fills the field definition array with information about each field. When you call it you will pass a BASIC file number you want to be used for later access, the full name of the file, a TYPE variable that receives the header information, and a TYPE array. The array is redimensioned within OpenDBF, and then filled with information about each field in the file.
CloseDBF is called when you want to close the file, and it is also responsible for updating the date and number of records information in the file header.
GetRecord and SetRecord retrieve and write individual records respectively. The calling program must specify the file and record numbers, and also pass a string that will receive the actual record data. GetRecord assumes that you have already created the string that is to receive data from the file. A Header variable is also required, so GetRecord and SetRecord will know the length of each record. Both GetRecord and SetRecord require the file to have already been opened using OpenDBF.
These routines are used to retrieve and assign the actual field data within a record string. The dbAccess routines cannot use a TYPE variable to define the records, since they must be able to accommodate any type of file. Therefore, the Record$ variable is created dynamically, and assigned and read as necessary. However, this also means that you may not refer to the fields by name as would be possible with a TYPE variable.
GetField returns the contents of the specified field, based on the field number; the complementary function GetFldName returns the field number based on the field name. SetField is the opposite of GetField, and it assigns a field into the Record$ variable. Padded$ serves as an assistant to SetField, and it ensures that the field contents are padded to the correct length with trailing blanks.
Deleted is an integer function that returns a value of -1 to indicate that the record string passed to it holds a deleted record, or 0 if the record is not deleted. The very first byte in each dBASE record is reserved just to indicate if the record has been deleted. An asterisk (*) in that position means the record is deleted; otherwise the field is blank. Using a function for this purpose lets you directly test a record using code such as IF Deleted%(Record$) THEN or IF NOT Deleted%(Record$) THEN.
Marking deleted records is a common technique in database programming, because the amount of overhead needed to actually remove a record from a file is hardly ever justified. The lost space is recovered in one of two ways: the most common is to copy the data from one file to another. Another, more sophisticated method instead keeps track of which records have been deleted. Then as new data is added, it is stored in the space that was marked as abandoned, thus overwriting the old data. The DBPACK.BAS program described later in this chapter uses the copy method, but uses a trick to avoid having to create a second file.
Several programs are presented to show the various dbAccess routines in context, and each is described individually below. DBSTRUCT.BAS displays the header structure of any dBASE file, DBCREATE.BAS creates an empty database file with header information only, and DBEDIT.BAS lets you browse, edit, and add records to an existing data file. These programs are simple enough to understand, even without excessive comments. However, highlights of each program's operation is given.
DBSTRUCT.BAS begins by including the DBF.BI file which defines the Header TYPE variable and the FldStruc() TYPE array. A short DEF FN-style function is used to simplify formatting when the file date is printed later in the program. Once you enter the name of the dBASE file to be displayed, a call is made to OpenDBF. OpenDBF accepts the incoming file number and name, and returns information about the file in Header and FldStruc(). The remainder of the program simply reports that information on the display screen.
'********* DBSTRUCT.BAS, displays a dBASE file's structure DEFINT A-Z '$INCLUDE: 'dbf.bi' '$INCLUDE: 'dbaccess.bi' DEF FnTrim$ (DateInfo) = LTRIM$(STR$(DateInfo)) DIM Header AS DBFHeadStruc REDIM FldStruc(1 TO 1) AS FieldStruc CLS LINE INPUT "Enter the DBF file name: ", DBFName$ IF INSTR(DBFName$, ".") = 0 THEN DBFName$ = DBFName$ + ".DBF" END IF CALL OpenDBF(1, DBFName$, Header, FldStruc()) CLOSE #1 PRINT "Structure of " + DBFName$ PRINT PRINT "Version: "; Header.Version PRINT "Last Update: "; FnTrim$(Header.Month); PRINT "/" + FnTrim$(Header.Day); PRINT "/" + FnTrim$(Header.Year) PRINT "# Records: "; Header.TRecs PRINT "Rec Length: "; Header.RecLen PRINT "# Fields: "; Header.TFields PRINT PRINT "Name", "Type", "Offset", "Length", "# Decimals" PRINT "----", "----", "------", "------", "----------" FOR X = 1 TO Header.TFields PRINT FldStruc(X).FName, PRINT FldStruc(X).FType, PRINT FldStruc(X).FOff, PRINT FldStruc(X).FLen, PRINT FldStruc(X).Dec NEXT END
The DBCREATE.BAS program accepts the name of a data file to create, and then asks how many fields it is to contain. Once the number of fields is known, a TYPE array is dimensioned to hold the information, and you are prompted for each field's characteristics one by one. As you can see by examining the program source listing, the information you enter is validated to prevent errors such as illegal field lengths, more decimal digits than the field can hold, and so forth.
As each field is defined in the main FOR/NEXT loop, the information you enter is stored directly into the FldStruc TYPE array. At the end of the loop, CreateDBF is called to create an empty .DBF data file.
'********** DBCREATE.BAS, creates a DBF file
DEFINT A-Z
'$INCLUDE: 'dbf.bi'
'$INCLUDE: 'dbaccess.bi'
CLS
LOCATE , , 1
LINE INPUT "Enter DBF name: "; DBFName$
IF INSTR(DBFName$, ".") = 0 THEN
DBFName$ = DBFName$ + ".DBF"
END IF
DO
INPUT "Enter number of fields"; TFields
IF TFields <= 128 THEN EXIT DO
PRINT "Only 128 fields are allowed"
LOOP
REDIM FldStruc(1 TO TFields) AS FieldStruc
FOR X = 1 TO TFields
CLS
DO
PRINT "Field #"; X
LINE INPUT "Enter field name: ", Temp$
IF LEN(Temp$) <= 10 THEN EXIT DO
PRINT "Field names are limited to 10 characters"
LOOP
FldStruc(X).FName = Temp$
PRINT "Enter field type (Char, Date, Logical, Memo, ";
PRINT "Numeric (C,D,L,M,N): ";
DO
Temp$ = UCASE$(INKEY$)
LOOP UNTIL INSTR(" CDLMN", Temp$) > 1
PRINT
FldStruc(X).FType = Temp$
FldType = ASC(Temp$)
SELECT CASE FldType
CASE 67 'character
DO
INPUT "Enter field length: ", FldStruc(X).FLen
IF FldStruc(X).FLen <= 255 THEN EXIT DO
PRINT "Character field limited to 255 characters"
LOOP
CASE 78 'numeric
DO
INPUT "Enter field length: ", FldStruc(X).FLen
IF FldStruc(X).FLen <= 19 THEN EXIT DO
PRINT "Numeric field limited to 19 characters"
LOOP
DO
INPUT "Number of decimal places: ", FldStruc(X).Dec
IF FldStruc(X).Dec < FldStruc(X).FLen THEN EXIT DO
PRINT "Too many decimal places"
LOOP
CASE 76 'logical
FldStruc(X).FLen = 1
CASE 68 'date
FldStruc(X).FLen = 8
CASE 77
FldStruc(X).FLen = 10
END SELECT
NEXT
CALL CreateDBF(DBFName$, FldStruc())
PRINT DBFName$; " created"
END
DBEDIT.BAS is the main demonstration program for the dbAccess subroutines. It prompts you for the name of the dBASE file to work with, and then calls OpenFile to open it. Once the file has been opened you may view records forward and backward, edit existing records, add new records, and delete and undelete records. Each of these operations is handled by a separate CASE block, making the code easy to understand.
'********** DBEDIT.BAS, edits a record in a DBF file
DEFINT A-Z
'$INCLUDE: 'dbf.bi'
'$INCLUDE: 'dbaccess.bi'
DIM Header AS DBFHeadStruc
REDIM FldStruc(1 TO 1) AS FieldStruc
CLS
LINE INPUT "Enter .DBF file name: ", DBFName$
IF INSTR(DBFName$, ".") = 0 THEN
DBFName$ = DBFName$ + ".DBF"
END IF
CALL OpenDBF(1, DBFName$, Header, FldStruc())
Record$ = SPACE$(Header.RecLen)
RecNum& = 1
RecChanged = 0
GOSUB GetTheRecord
DO
PRINT "What do you want to do (Next, Prior, Edit, ";
PRINT "Delete, Undelete, Add, Quit)? ";
SELECT CASE UCASE$(INPUT$(1))
CASE "N"
IF RecChanged THEN
CALL SetRecord(1, RecNum&, Record$, Header)
END IF
RecNum& = RecNum& + 1
IF RecNum& > Header.TRecs THEN
RecNum& = 1
END IF
GOSUB GetTheRecord
CASE "P"
IF RecChanged THEN
CALL SetRecord(1, RecNum&, Record$, Header)
END IF
RecNum& = RecNum& - 1
IF RecNum& < 1 THEN
RecNum& = Header.TRecs
END IF
GOSUB GetTheRecord
CASE "E"
Edit:
PRINT
INPUT "Enter the field number:"; Fld
DO
PRINT "New "; FldStruc(Fld).FName;
INPUT Text$
IF LEN(Text$) <= FldStruc(Fld).FLen THEN EXIT DO
PRINT "Too long, only "; FldStruc(Fld).FLen
LOOP
CALL SetField(Record$, Text$, Fld, FldStruc())
RecChanged = -1
GOSUB DisplayRec
CASE "D"
MID$(Record$, 1) = "*"
RecChanged = -1
GOSUB DisplayRec
CASE "U"
MID$(Record$, 1, 1) = " "
RecChanged = -1
GOSUB DisplayRec
CASE "A"
Header.TRecs = Header.TRecs + 1
RecNum& = Header.TRecs
LSET Record$ = ""
GOTO Edit
CASE ELSE
EXIT DO
END SELECT
LOOP
IF RecChanged THEN
CALL SetRecord(1, RecNum&, Record$, Header)
END IF
CALL CloseDBF(1, Header.TRecs)
END
GetTheRecord:
CALL GetRecord(1, RecNum&, Record$, Header)
DisplayRec:
CLS
PRINT "Record "; RecNum&; " of "; Header.TRecs;
IF Deleted%(Record$) THEN PRINT " (Deleted)";
PRINT
PRINT
FOR Fld = 1 TO Header.TFields
FldText$ = GetField$(Record$, Fld, FldStruc())
PRINT FldStruc(Fld).FName, FldText$
NEXT
PRINT
RETURN
DBPACK.BAS is the final dBASE utility, and it shows how to write an optimized packing program. Since there is no reasonable way to actually erase a record from the middle of a file, dBASE (and indeed, most database programs) reserve a byte in each record solely to show if it has been deleted. The DBPACK.BAS utility program is intended to be run periodically, to actually remove the deleted records.
Most programs perform this maintenance by creating a new file, copying only the valid records to that file, and then deleting the original data file. In fact, this is what dBASE does. The approach taken by DBPACK is much more intelligent in that it works through the file copying good records on top of deleted ones. When all that remains at the end of the file is data that has been deleted or abandoned copies of records, the file is truncated to a new, shorter length. The primary advantage of this approach is that it saves disk space. This is superior to the copy method that of course requires you to have enough free space for both the original data and the copy. Because the actual data file is manipulated instead of a copy, be sure to have a recent backup in case a power failure occurs during the packing process.
DBPACK.BAS is fairly quick, but it could be improved if records were processed in groups, rather than one at a time. This would allow more of the swapping to take place in memory, rather than on the disk. However, DBPACK was kept simple on purpose, to make its operation clearer.
There is no BASIC or DOS command that specifically truncates a file, so this program uses a little-known trick. If a program calls DOS telling it to write zero bytes to a file, DOS truncates the file at the current seek location. Since BASIC does not allow you to write zero bytes, CALL Interrupt must be used to perform the DOS call. Note that you can also use this technique to extend a file beyond its current length. This will be described in more detail in Chapter 11, which describes using CALL Interrupt to access DOS and BIOS services.
'********* DBPACK.BAS, removes deleted records from a file
'NOTE: Please make a copy of your DBF file before running this program.
' Unlike dBASE that works with a copy of the data file, this program
' packs, swaps records, and then truncates the original data file.
DEFINT A-Z
'$INCLUDE: 'dbf.bi'
'$INCLUDE: 'dbaccess.bi'
'$INCLUDE: 'regtype.bi'
DIM Registers AS RegType
DIM Header AS DBFHeadStruc
REDIM FldStruc(1 TO 1) AS FieldStruc
LINE INPUT "Enter the dBASE file name: ", DBFName$
IF INSTR(DBFName$, ".") = 0 THEN
DBFName$ = DBFName$ + ".DBF"
END IF
CALL OpenDBF(1, DBFName$, Header, FldStruc())
Record$ = SPACE$(Header.RecLen)
GoodRecs& = 0
FOR Rec& = 1 TO Header.TRecs
CALL GetRecord(1, Rec&, Record$, Header)
IF NOT Deleted%(Record$) THEN
CALL SetRecord(1, GoodRecs& + 1, Record$, Header)
GoodRecs& = GoodRecs& + 1
END IF
NEXT
'This trick truncates the file
RecOff& = (GoodRecs& * Header.RecLen) + Header.FirstRec
Eof$ = CHR$(26)
PUT #1, RecOff&, Eof$
SEEK #1, RecOff& + 1
Registers.AX = &H4000 'service to write to a file
Registers.BX = FILEATTR(1, 2) 'get the DOS handle
Registers.CX = 0 'write 0 bytes to truncate
CALL Interrupt(&H21, Registers, Registers)
CALL CloseDBF(1, GoodRecs&)
PRINT "All of the deleted records were removed from ";
PRINT DBFName$
PRINT GoodRecs&; "remaining records"
The primary limitation of the DBF file format is it does not allow complex data types. With support for only five basic field types--Character, Date, Logical, Memo, and Numeric--it is very limited when compared to what BASIC allows. However, you can easily add new data types to the programs you write using extensions to the standard field format. Since a byte is used to store the field type in the dBASE file header, as many as 256 different types are possible (0 through 255). You would simply define additional code numbers for field types such as Money or Time, or perhaps other Logical field types such as M and F (Male and Female).
Another useful enhancement would be to store numeric values in their native fixed-length format, instead of using the much slower ASCII format that dBASE uses. You could also modify the header structure itself, to improve the performance of your programs. Since BASIC does not offer a single byte numeric data type, it would make sense to replace the STRING * 1 variables with integers. This would eliminate repeated use of ASC and CHR$ when reading and assigning single byte strings. You could also change the date storage method to pack the date fields to three characters--one for the year, one for the month, and another for the day. Of course, if you do change the header or data format, then your files will no longer be compatible with the dBASE standard.
At some point, the number of records in a database file will grow to the point where it takes longer and longer to locate information in the file. This is where indexing can help. Some of the principles of indexed file access were already described in Chapter 5, in the section that listed the BASIC PDS ISAM compiler switches. In this section I will present more details on how indexing works, and also show some simple methods you can create yourself. Although there are nearly as many indexing systems as there are programmers, one of the most common is the sorted list.
A sorted list is simply a parallel TYPE array that holds the key field and a record number that corresponds to the data in the main file. By maintaining the array in sorted order based on the key field information, the entire database may be accessed in sorted, rather than sequential order. A typical TYPE array used as a sorted list for indexing would look like this:
TYPE IndexType LastName AS STRING * 15 RecNum AS LONG END TYPE REDIM IArray(1 TO TotalRecords) AS IndexType
Assuming each record in the data file has a corresponding element in the TYPE array, locating a given record is as simple as searching the array for a match. Since array searches in memory are much faster than reading a disk file, this provides an enormous performance boost when compared to reading each record sequentially. To conserve memory and also further improve searching speed, you might use a shorter string portion for the last name.
The following short program shows how such an index array could be sorted.
FOR X% = MaxEls TO 1 STEP -1
FOR Y% = 1 TO X% - 1
IF IArray(Y%).LastName > IArray(Y% + 1).LastName THEN
SWAP IArray(Y%), IArray(Y% + 1)
END IF
NEXT
NEXT
Here, the sorting is based on the last name portion of the TYPE elements. Once the array is sorted, the data file may be accessed in order by walking through the record numbers contained in the RecNum portion of each element:
DIM RecordVar AS IndexType FOR X% = 1 TO MaxEls GET #1, IArray(X%).RecNum, RecordVar PRINT RecordVar.LastName NEXT
Likewise, to find a given name you would search the index array based on the last name, and then use the record number from the same element once it is found:
Search$ = "Cramer"
FOR X% = 1 TO MaxEls
IF IArray(X%).LastName = Search$ THEN
Record% = IArray(X%).RecNum
GET #1, Record%, RecordVar
PRINT "Found "; Search$; " at record number"; Record%
EXIT FOR
END IF
NEXT
Chapter 8 will discuss sorting and searching in detail using more sophisticated algorithms than those shown here, and you would certainly want to use those for your program. However, one simple improvement you could make is to reduce the number of characters in each index entry. For example, you could keep only the first four characters of each last name. Although this might seem to cause a problem--searching for Jackson would also find Jack--you would have the same problem if there were two Jacksons. The solution, therefore, is to retrieve the entire record if a partial match is found, and compare the complete information in the record with the search criteria.
Inserting an entry into a sorted list requires searching for the first entry that is greater than or equal to the one you wish to insert, moving the rest of the entries down one notch and inserting the new entry. The code for such a process might look something like this:
FOR X% = 2 TO NumRecs%
IF Item.LastName <= Array(X%).LastName THEN
IF Item.LastName >= Array(X% - 1).LastName THEN
FOR Y% = NumRecs% TO X% STEP -1
SWAP Array(Y%), Array(Y% + 1)
NEXT
Array(X%) = Item
EXIT FOR
END IF
END IF
NEXT
Understand that this code is somewhat simplified. For example, it will not correctly handle inserting an element before the first existing entry or after the last. Equally important, unless you are dealing with less than a few hundred entries, this code will be extremely slow. The loop that inserts an element by swapping all of the elements that lie beyond the insertion point will never be as efficient as a dedicated subroutine written in assembly language. Commercial toolbox products such as Crescent Software's QuickPak Professional include memory moving routines that are much faster than one written using BASIC.
Finally, you must have dimensioned the array to at least one more element than there are records, to accommodate the inserted element. Many programs that use in-memory arrays for indexing dimension the arrays to several hundred extra elements to allow new data to be entered during the course of the session. Since BASIC 7.1 offers the REDIM PRESERVE command, that too could be used to extend an array as new data is added.
Expression evaluation, in the context of data management, is the process of evaluating a record on the basis of some formula. Its uses include the creation of index keys, reports, and selection criteria. This is where the application of independent file structures such as the dBASE example shows a tremendous advantage. For example, if the user wants to be able to view the file sorted first by zip code and then by last name, some means of performing a multi-key sort is required.
Another example of expression evaluation is when multiple conditions using AND and OR logic are needed. You may want to select only those records where the balance due is greater than $100 *and* the date of last payment is more than 30 days prior to the current date. Admittedly, writing an expression parser is not trivial; however, the point is that data-driven programming is much more suitable than code-driven programming in this case.
Without some sort of look-up table in which you can find the field names and byte offsets, you are going to have a huge number of SELECT CASE statements, none of which are reusable in another application. Indeed, one of the most valuable features of AJS Publishing's db/LIB add-on database library is the expression evaluator it includes. This routine lets you maintain the data structure in a file, and the same code can be used to process all file search operations.
Most programmers are familiar with traditional random access files, where a fixed amount of space is set aside in each record to hold a fixed amount of information. For very simple applications this method is sensible, and allows for fast access to each record provided you know the record number. As you learned earlier in this chapter, indexing systems can eliminate the need to deal with record numbers, instead letting you locate records based on the information they contain. Relational databases take this concept one step further, and let you locate records in one file based on information contained in another file. As you will see, this lets you create applications that are much more powerful than those created using standard file handling methods.
Imagine you are responsible for creating an order entry program for an auto parts store. At the minimum, three sets of information must be retained in such a system: the name, address, and phone number of each customer; a description of each item that is stocked and its price; and the order detail for each individual sale. A simplistic approach would be to define the records in a single database with fields to hold the customer information and the products purchased, with a new record used for each transaction. A TYPE definition for these records might look like this:
TYPE RecordType InvoiceNum AS INTEGER CustName AS STRING * 32 CustStreet AS STRING * 32 CustCity AS STRING * 15 CustState AS STRING * 2 CustZip AS STRING * 5 CustPhone AS STRING * 10 Item1Desc AS STRING * 15 Item1Price AS SINGLE Quantity1 AS INTEGER Item2Desc AS STRING * 15 Item2Price AS SINGLE Quantity2 AS INTEGER Item3Desc AS STRING * 15 Item3Price AS SINGLE Quantity3 AS INTEGER Item4Desc AS STRING * 15 Item4Price AS SINGLE Quantity4 AS INTEGER TaxPercent AS SINGLE InvoiceTot AS SINGLE END TYPE
As sensible as this may seem at first glance, there are a number of problems with this record structure. The primary limitation is that each record can hold only four purchase items. How could the sales clerk process an order if someone wanted to buy five items? While room could be set aside for ten or more items, that would waste disk space for sales of fewer items. Worse, that still doesn't solve the inevitable situation when someone needs to buy eleven or more items at one time.
Another important problem is that the customer name and address will be repeated for each sale, further wasting space when the same customer comes back a week later. Yet another problem is that the sales personnel are responsible for knowing all of the current prices for each item. If they have to look up the price in a printout each time, much of the power and appeal of a computerized system is lost. Solving these and similar problems is therefore the purpose of a relational database.
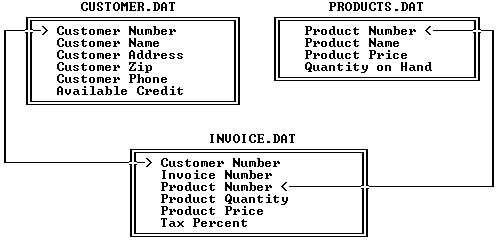
In a relational database, three separate files would be employed. One file will hold only the customer names and addresses, a second will hold just the item information, and a third is used to store the details of each invoice. In order to bind the three files together, a unique number must be assigned in each record. This is shown as a list of field names in Figure 7-1 below.
Now, when Bob Jones goes into the store to buy a radiator cap and a case of motor oil, the clerk can enter the names Jones and see if Bob is already a customer. If so, the order entry program will retrieve Bob's full name and address from the customer file and display it on the screen. Otherwise it would prompt the clerk to enter Bob's name and address. When Bob tells the clerk what he wants to buy, the clerk would enter the part number or name, and the program will automatically look up the price in the products file. (A smart program would even subtract the number of radiator caps from the "Quantity on Hand" field, so a report run at the end of each day can identify items that need to be ordered.) Once the sale is finalized, two new records will be written to the invoice file--one for the radiator cap and one for the motor oil.
Each invoice record would store Bob's customer number, a program- generated sequential invoice number, the product number, the quantity of this product sold, and the unit price. There's no need to store the subtotal, since that information could be recreated at any time from the quantity and unit price fields. If sales tax is charged, that field could hold just the rate. Again the actual tax amount could be computed at any time. The beauty of this organization is that there is never a need to store duplicated information, and thus there is no wasted disk space.
The relational aspect of this system becomes clear when it is time to produce a report. To print an invoice, the program searches the invoice file for every record with the unique invoice number. From the customer number field the customer's name and address are available, by searching for a match between the customer number in the invoice record and that same unique number in the customer file. And from the part number field the part name can be retrieved, based on finding the same part number in the products file. Thus, the term relational is derived from the ability to relate information in one file to information in a different file, based on unique identifying values. In this case, those values are the invoice number, the customer number, and the part number.
An important current trend in data processing is the use of Structured Query Language (SQL). The appeal of SQL is that it eliminates explicit coding in a conventional high-level language such as BASIC. Instead, SQL is an even higher-level language that performs most of the low-level details for you. SQL is based on passing SQL commands--called requests-- as strings, which are evaluated by the SQL engine. The short example program below shows some typical SQL commands in context.
select lastname, firstname, accountcode, phone from customers where unpaid > credit * .75 and today - duedate > 30 order by accountcode
When these commands are sent to the SQL server, the server responds by filling in an array with the resultant data. The beauty of SQL, therefore, is that it eliminates the SELECT CASE statements that you would have to write, and that would be specific to a given data file. In SQL, the data fields are accessed by name instead of by numeric offsets. The SQL program does not have to specify which data is double precision, and which is text, and so forth. Rather, all that is needed is the name of the data being reported on, the selection criteria, and the order in which the data is to be returned.
This program asks to report on the lastname, firstname, accountcode, and phone fields of the data set (file) named customers. It then specifies that only those customers who owe more than 75 percent of their available credit and are more than 30 days overdue should be listed. Finally, the customers are to be listed in order based on their customer account code number.
As a further example of the power of the SQL language, imagine you have written an application to manage a publishing business. In this hypothetical situation, three of the tables in your database are Stores, Titles, and Sales, which hold the names of each retail store, the book titles offered for sale, and the details of each sale.
Now, consider the problem of producing a report showing the total sales in dollars, with individual subtotals for each store. This would first require you generate a list of stores from the Stores table. You would then have to examine each sale in the Sales table, and each entry there would refer to a title which must be looked up in the Titles file to determine the price. You would then multiply this price by the quantity and add that to a running total being kept for each store, perhaps storing the result in a multi-dimensional array.
As you can see, this is potentially a lot of coding if you attempt to tackle the job using BASIC. While the sequence of SQL commands necessary to retrieve this information is not trivial either, it is certainly less work than writing an equivalent report in BASIC. Here are the SQL commands that perform the store sales report described above:
select stores.storename, sum(sales.qty * titles.price) from stores, titles, sales where stores.store_id = sales.store_id and titles.title_id = sales.title_id group by storename
As you can see from these short examples, SQL is a simple and intuitive language, and it may well be worth your effort to learn if you specialize in database programming or plan to. One excellent product you may wish to become familiar with is DataEase, a popular PC database product. One of the earliest adopters of SQL-style methods, DataEase lets even the novice user create sophisticated data entry forms and reports in a very short time. Contrast that with procedural languages such as that used by dBASE which require as much effort as programming in BASIC.
There are several good books that go into far greater detail about SQL than can possibly be offered here. One I recommend is "The Practical SQL Handbook: Using Structured Query Language" by Emerson, Darnovsky, and Bowman; Addison-Wesley Publishing Company; 1989. This book is clearly written, avoids the use of jargon, and contains numerous good explanations of what SQL is all about without getting bogged down in esoteric details.
Although network file access has been supported since QuickBASIC version 1.0, many programmers do not fully understand how to use this important feature. However, the concepts are simple once you know the commands. In the earlier auto parts store example, it was assumed that only one computer would be used to enter sales information. But when there are many sales people entering information all at once, some means is needed to let each computer access simultaneously a single group of files from a remote file server.
In this section I will discuss two methods for sharing files--one which is supported by BASIC, and the other supported only indirectly. I will also discuss methods for protecting data across the network and detecting which type of network is being used.
BASIC offers three commands to allow multiple programs to share files from a central, remote computer: OPEN, LOCK, and UNLOCK. Chapter 6 discussed the OPEN command in great detail, but mentioned the various file sharing options only briefly. OPEN provides four variations that let you specify what other processes have access to the file being opened. For simplicity, the discussions that follow assume the files are being opened for random access; this is the most common access method when writing databases. But only very slight changes are needed to adapt this information for use with binary file access as shown in the earlier dBASE examples.
When you add SHARED to the list of OPEN arguments, you are telling the operating system that any other program may also open the file while you are using it. [Without SHARED, another program that tries to open a file you have opened will receive an "Access denied" error message.] Once the other programs have opened the file they may freely read from it or write to it. If you need to restrict what operations other programs may perform, you would replace SHARED with either LOCK READ, LOCK WRITE, or LOCK READ WRITE. LOCK READ prevents other program from reading the file while you have it open, although they could write to it. Likewise, LOCK WRITE lets another process read from the file but not write to it. LOCK READ WRITE of course prevents another program from either reading or writing the file.
Because of these complications and limitations, you will most likely use SHARED to allow full file sharing. Then, the details of who writes what and when can be handled by logic in your program, or by locking individual records.
Note that with most networks you cannot open a file for shared access, unless you have previously loaded SHARE.EXE that comes with DOS 3.0 and later versions. SHARE.EXE is a TSR (terminate and stay resident) program that manages *lock tables* for your machine. These tables comprise a list showing which portions of what files are currently locked. A short utility that reports if SHARE.EXE is installed is presented later in this chapter. Some networks, however, require SHARE to be installed only on the computer that is acting as the file server.
The most difficult problem you will encounter when writing a program that runs on a network is arbitrating when each user will be allowed to read and write data. Since more than one operator may call up a given record at the same time, it is possible--even likely--that changes made by one person will be overwritten later by another. Imagine that two operators have just called up the same customer record on their screens. Further, one operator has just changed the customer's address and the other has just changed the phone number. Then the first operator then saves the record with the new address, but two seconds later the second operator saves the same record with a new phone number. In this case, the second disk write stores the old address on top of the same record that was saved two seconds earlier!
To prevent this from happening requires some type of file locking, whereby the second operator is prevented from even loading the record; the program instead gives them a message saying the record is already in use. There are two primary ways to do this. A *hard lock* is implemented using the BASIC LOCK statement, and it causes the network operating system to deny access to the record if the first program has locked it. A *soft lock* is similar, except it uses program logic that you design to determine if the file is already in use. Let's take a closer at each of these locking methods.
A hard lock is handled by the network software, and is controlled by the BASIC LOCK and UNLOCK statements. Hard locks may be specified for all or just a part of a file. When a program imposes a hard lock, all other programs are prevented from either reading or writing that portion of the file. You may lock either one record or a range of records: LOCK #1, 3 locks record 3, and UNLOCK #1, 1 TO 10 unlocks records 1 through 10. Files that have been opened for binary access may also be locked, by specifying a range of bytes instead of one or more record numbers.
Because access to the specified record or range of records is denied to all other applications, it is important to unlock the records as soon as you are done with them. A code fragment that shows how to manipulate a record using hard locking would look like this:
OPEN "CUST.DAT" SHARED AS #1 LEN = RecordLength% LOCK #1, RecNum% GET #1, RecNum%, RecData 'allow the user to edit the record here PUT #1, RecNum%, RecData UNLOCK #1, RecNum% CLOSE #1
There are several fundamental problems with hard locks you must be aware of. First, they prevent another application from even looking at the data that is locked. If a record is tied up for a long period of time, this prevents another program from reporting on that data. Another is that all locks must be removed before the file is closed. The BASIC PDS language reference manual warns, "Be sure to remove all locks with an UNLOCK statement before closing a file or terminating your program. Failing to remove locks produces unpredictable results." [As in "Yo, get out the Norton disk doctor".]
Yet another problem is that each LOCK must have an exactly corresponding UNLOCK statement. It is therefore up to your program to know exactly which record or range of records were locked earlier, and unlock the exact same records later on.
Finally, the last problem with hard locking is that it requires you to use ON ERROR. If someone else has locked a record and you attempt to read it, BASIC will generate a "Permission denied" error that must be trapped. Since there's no way for you to know ahead of time if a record is available or locked you must be prepared to handle the inevitable errors. Similarly, if you attempt to lock a record when it has already been locked by another program, BASIC will create an error. It is possible to lock and unlock records behind BASIC's back using CALL Interrupt and detect those errors manually; however, soft locks often provide an even better solution.
A soft lock is implemented using logic you design, which has the decided advantage of letting you customize that logic to your exact needs. Most programs implement a soft lock by reserving a single byte at the beginning of each data record. This is similar to the method dBASE uses to identify deleted records. Understand that the one important limitation of soft locks is that all programs must agree on the method being used. Unless you wrote (or at least control) all of the other programs that are sharing the file, soft locks will probably not be possible.
One way to implement a soft lock is to use a special character--perhaps the letter "L"--to indicate that a record is in use and may not be written to. Therefore, to lock a record you would first retrieve it, and then check to be sure it isn't already locked. If it is not currently locked you would assign an "L" to the field reserved for that purpose, and finally write the record back to disk. Thereafter, any other program can tell that the record is locked by simply examining that first byte.
If someone tries to access a record that is locked, the program can display the message "Record in use" or something along those lines. A simple enhancement to this would store a user identification number in the lock field, rather than just a locked identifier. This way the program could also report who is using the record, and not just that it is locked. This is shown in context below.
GET #1, RecNum%, RecData$
Status$ = LEFT$(RecData$, 1)
SELECT CASE Status$
CASE " " 'Record is okay to write, lock it now
MID$(RecData$, 1) = CHR$(UserID)
PUT #1, RecNum%, RecData$
GOTO EditRecord
CASE "*" 'Record is deleted, say so
PRINT "Record number"; RecNum%; " is deleted."
GOTO SelectAnotherRecord
CASE ELSE 'Status$ contains the user number
PRINT "Record already in use by user: "; Status$
GOTO ReadOnly
END SELECT
...
...
SaveRecord:
MID$ (RecData$, 1) = " " 'clear the lock status
PUT #1, RecNum%, RecData$ 'save the new data to disk
Many networks require that SHARE.EXE be installed before a file may be opened for shared access, you can avoid runtime errors by being able to determine ahead of time if this file is loaded. The following short function and example returns either -1 or 0 to indicate if SHARE is currently loaded or not, respectively.
DEFINT A-Z DECLARE FUNCTION ShareThere% () '$INCLUDE: 'regtype.bi' FUNCTION ShareThere% STATIC DIM Registers AS RegType ShareThere% = -1 'assume Share is loaded Registers.AX = &H1000 'service 10h CALL Interrupt(&H2F, Registers, Registers) AL = Registers.AX AND 255 'isolate the result in AL IF AL <> &HFF THEN ShareThere% = 0 END FUNCTION
Then, at the start of your program you would invoke ShareThere, and display an error message if SHARE has not been run:
IF NOT ShareThere% () THEN PRINT "SHARE.EXE is not installed" END END IF
Another feature of a well-behaved network application is to determine if the correct network operating system is installed. In most cases, unless you are writing a commercial application for others to use, you'll already know which operating system is expected. However, it is possible to determine with reasonable certainty what network software is currently running. The three functions that follow must be invoked in the order shown, and they help you determine the brand of network your program is running under.
'********** NETCHECK.BAS, identifies the network brand
DEFINT A-Z
'$INCLUDE: 'regtype.bi'
DECLARE FUNCTION NWThere% ()
DECLARE FUNCTION BVThere% ()
DECLARE FUNCTION MSThere% ()
DIM SHARED Registers AS RegType
PRINT "I think the network is ";
IF NWThere% THEN
PRINT "Novell Netware"
ELSEIF BVThere% THEN
PRINT "Banyon Vines"
ELSEIF MSThere% THEN
PRINT "Lantastic or other MS compatible"
ELSE
PRINT "Something I don't recognize, or no network"
END IF
END
FUNCTION BVThere% STATIC
BVThere% = -1
Registers.AX = &HD701
CALL Interrupt(&H2F, Registers, Registers)
AL = Registers.AX AND 255
IF AL <> 0 THEN BVThere% = 0
END FUNCTION
FUNCTION MSThere% STATIC
MSThere% = -1
Registers.AX = &HB800
CALL Interrupt(&H2F, Registers, Registers)
AL = Registers.AX AND 255
IF AL = 0 THEN MSThere% = 0
END FUNCTION
FUNCTION NWThere% STATIC
NWThere% = -1
Registers.AX = &H7A00
CALL Interrupt(&H2F, Registers, Registers)
AL = Registers.AX AND 255
IF AL <> &HFF THEN NWThere% = 0
END FUNCTION
There are several tools on the market that can help you to write database applications. Although BASIC includes many of the primitive services necessary for database programming, there are several limitations. Four such products are described briefly below, and all are written in assembly language for fast performance and small code size. You should contact the vendors directly for more information on these products.
This is one of the most popular database add-on products for use with BASIC, and rightfully so. db/LIB comes in both single- and multi-user versions, and handles all aspects of creating, updating, and indexing relational database files. db/LIB uses the dBASE III+ file format which lets you access files from many different applications. Besides its database handling routines, db/LIB includes a sophisticated expression evaluator that lets you select records based on multiple criteria. Compared to many other database libraries, db/LIB is extremely fast, and is also very easy to use.
db/LIB AJS Publishing, Inc. P.O. Box 83220 Los Angeles, CA 90083 213-215-9145
Btrieve has been around for a very long time, and like db/LIB it lets you easily manipulate all aspects of a relational database. Unlike db/LIB, however, Btrieve can be used with nearly any programming language. The downside is that Btrieve is more complicated to use with BASIC. Also, a special TSR program must be run before your program can call its routines, further complicating matters for your customers. But Btrieve has a large and loyal following, and if you write programs using more than one language it is certainly a product to consider.
Btrieve Novell, Inc. 122 East 1700 SOuth Provo, UT 84606 801-429-7000
Index Manager is an interesting and unique product, because it handles only the indexing portion of a database program. Where most of the other database add-ons take over all aspects of file creation and updating, Index Manager lets you use any file format you want. Each time a record is to be retrieved based on a key field, a single call obtains the appropriate record number. Index Manager is available in single- and multi-user versions, and is designed to work with compiled BASIC only.
Index Manager CDP Consultants 1700 Circo del Cielo Drive El Cajon, CA 92020 619-440-6482
Ocelot is unique in that it uses SQL commands instead of the more traditional approach used by the other products mentioned. Ocelot supports both standalone and networked access, and it is both fast and flexible. Although Ocelot is meant for use with several different programming languages, the company provides full support for programmers using BASIC.
Ocelot Ocelot Computer Services #1502, 10025-106 Street Edmonton, Alberta Canada T5J 1G7 403-421-4187
In this chapter you learned the principles of data-driven programming, and the advantages this method offers. Unlike the TYPE definition method that Microsoft recommends, storing record and field information as variables allows your programs to access any type of data using the same set of subroutines.
You also learned how to create and access data using the popular dBASE file format, which has the decided advantage of being compatible with a large number of already successful commercial products. A complete set of dBASE file access tools was presented, which may be incorporated directly into your own programs.
This chapter also explained indexing methods, to help you quickly locate information stored in your data files. Besides providing fast access, indexes help to maintain your data in sorted order, facilitating reports on that data. Relational databases were described in detail, using examples to show the importance of maintaining related information in separate files. As long as a unique key value is stored in each record, the information can be joined together at any time for reporting and auditing purposes. SQL was also mentioned, albeit briefly, to provide a glimpse into the future direction that database programming is surely heading.
In the section about programming for a network, a comparison of the various file sharing and locking methods was given. You learned the importance of preventing one program from overwriting data from another, and examined specific code fragments showing two different locking techniques.
Finally, several third-party library products were mentioned. In many situations it is more important to get the job done than to write all of the code yourself. When the absolute fastest performance is necessary, a well written add-on product can often be the best solution to a complex data management problem.
The next chapter discusses searching and sorting data both in memory and on disk, and provides a logical extension to the information presented here. In particular, there are a number of ways that you can speed up index searches using either smarter algorithms, assembly language, or both.
| Ā |